The world of AI is moving at lightning speed! Just when you think you've got a handle on the latest and greatest, a new model pops up promising more power, better performance, or perhaps, a more accessible price point. Today, we're going to shine a spotlight on Google's Gemini 2.5 Flash, a model that's making waves for its impressive capabilities packed into a cost-effective package.
What is Gemini 2.5 Flash?
Think of Gemini 2.5 Flash as a nimble and efficient member of the Gemini family. It's designed to be a faster and more cost-effective option compared to its larger sibling, Gemini 2.5 Pro, while still offering strong performance on a variety of tasks. Google has rolled out an early preview version of Gemini 2.5 Flash, making it available to developers through the Gemini API, Google AI Studio, and Vertex AI.
One of the standout features of the Gemini 2.5 models, including Flash, is their "thinking" capability. Unlike models that just spit out a response immediately, these models can go through a reasoning process to better understand complex prompts, break down tasks, and plan their answers. This is particularly helpful for tasks that require multiple steps of logic, like solving tricky math problems or digging into research questions. Gemini 2.5 Flash is noted for performing well on benchmarks requiring complex reasoning.
Performance and Price: Finding the Sweet Spot
When we look at AI models, we often consider a balance between performance and cost. Gemini 2.5 Flash aims to hit a sweet spot here. According to information shared by Google, 2.5 Flash offers comparable metrics to other leading models while being significantly more cost-efficient.
Let's look at some of the performance highlights based on available data:
- Reasoning & Knowledge: In benchmarks like Humanity's Last Exam (without tools), Gemini 2.5 Flash (with thinking) scores 12.1%. While other models like OpenAI's o4-mini score higher at 14.3%, Gemini 2.5 Flash offers a compelling alternative, especially when considering cost.
- Science & Mathematics: Gemini 2.5 Flash shows strong performance in science and math benchmarks. For instance, in the GPQA diamond science benchmark (single attempt), it scores 78.3%, and in Mathematics AIME 2024 (single attempt), it achieves 88.0%.
- Coding: In code generation (LiveCodeBench v5, single attempt), Gemini 2.5 Flash scores 63.5%. For code editing (Aider Polyglot), it scores 51.1% (whole) and 44.2% (diff-fenced). Some users have noted that while 2.5 Flash is faster than 2.5 Pro, it might be slightly less capable at complex coding tasks or "vibe coding." However, others have found it effective for tasks like data extraction and transformation.
- Visual Reasoning and Image Understanding: Gemini 2.5 Flash performs well in visual reasoning (MMMU, single attempt) at 76.7% and image understanding (Vibe-Eval/Reka) at 62.0%. Interestingly, there's a hidden capability for image inputs where the model can generate 2D bounding boxes and even segmentation masks, which is quite powerful at this price point.
- Long Context: With a long context window of 128k (average) and 1M (pointwise), Gemini 2.5 Flash demonstrates strong performance in the MRCR benchmark, scoring 84.6% and 66.3% respectively.
- Multilingual Performance: The model also shows solid multilingual capabilities, scoring 88.4% on the Global LLM Lite benchmark.
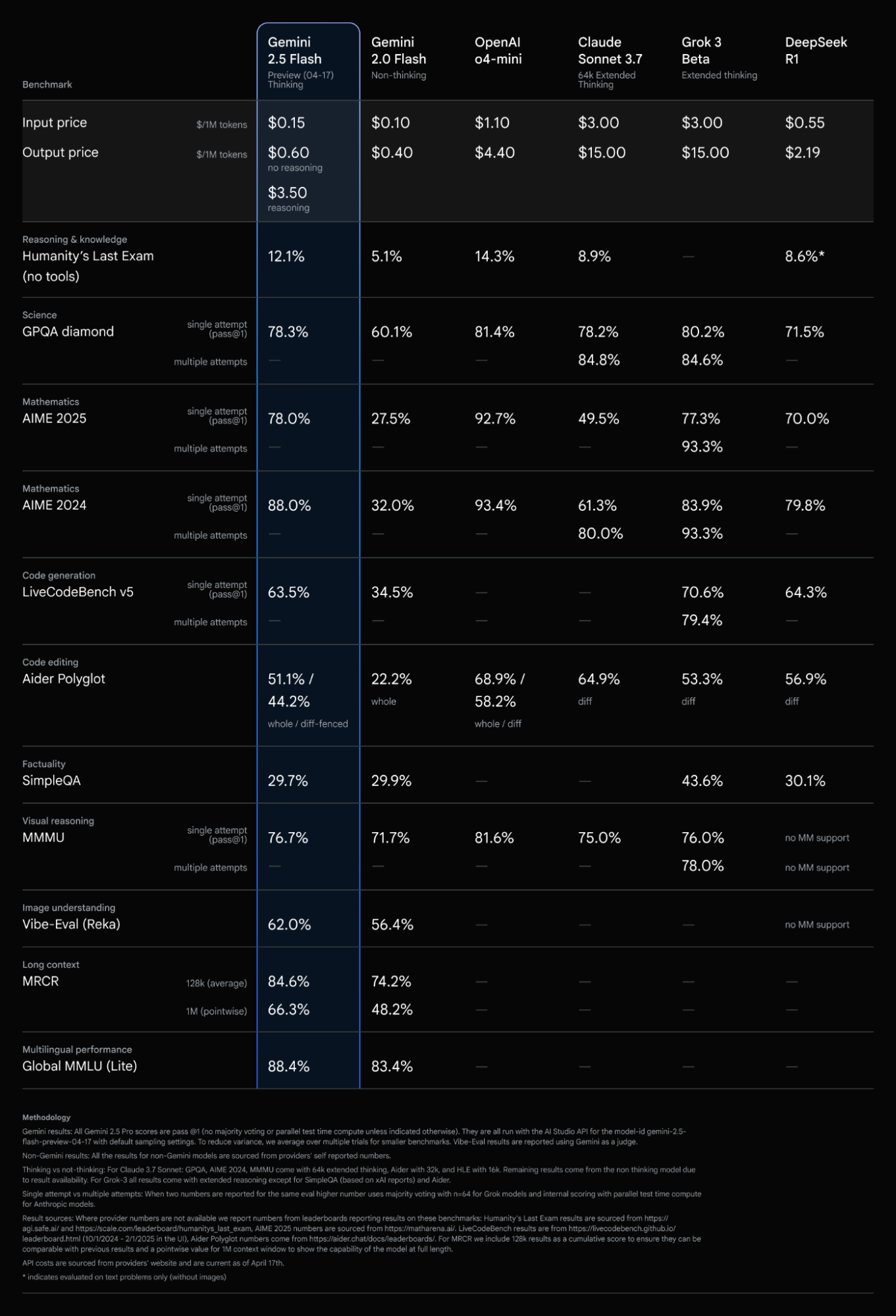
Now, let's talk about the cost. The pricing structure for Gemini 2.5 Flash is designed to be competitive. For input tokens, it's priced at $0.15 per 1M tokens, and for output tokens, it's $0.60 per 1M tokens without reasoning and $3.50 per 1M tokens with reasoning enabled. This tiered pricing based on whether the thinking process is used gives developers flexibility to manage costs and latency depending on the task.
The "Thinking Budget" Explained
One of the unique aspects of Gemini 2.5 Flash is the ability to control its "thinking budget." Since these models can reason through their thoughts before generating a response, you can set a specific token budget for this thinking process.
- Thinking Off (Budget = 0): This is the most cost-effective and lowest-latency option. The model will generate a response without an explicit reasoning step, similar to how earlier models might function. This can still offer improved performance over previous models like 2.0 Flash.
- Thinking On (Budget > 0): By setting a thinking budget, you allow the model to perform that internal reasoning. The model is trained to automatically determine how much thinking is needed based on the complexity of your prompt, up to the budget you set. This can lead to more accurate and comprehensive answers for complex tasks, but it will increase the cost and potentially the latency.
This fine-grained control is a big deal because it lets you tailor the model's behavior to your specific needs and budget.
Real-World Impressions and Use Cases
Beyond the benchmarks, what are people saying about Gemini 2.5 Flash in the real world? Users have noted its speed, finding it significantly faster than 2.5 Pro. For many basic tasks, the performance is comparable to 2.5 Pro.
Its cost-efficiency makes it particularly appealing for high-volume tasks. For example, some users have found Gemini Flash models to be very effective and cost-viable for tasks like classifying and extracting attributes from large datasets. The ability to process thousands of data points for a relatively low cost is a significant advantage for businesses.
The multimodal capabilities, including image understanding and the potential for generating segmentation masks, open up interesting use cases in areas like data processing and analysis involving visual information.
Building with Gemini 2.5 Flash and MindPal
Understanding the capabilities and cost of models like Gemini 2.5 Flash is crucial when you're looking to build AI-powered solutions. Platforms like MindPal are designed to help you leverage the power of these advanced models by allowing you to build custom AI agents and multi-agent workflows.
With MindPal, you can create specialized AI agents tailored to specific tasks, and then connect them together in workflows using various nodes like the Agent Node, Human Input Node, Loop Node, and more. This allows you to automate complex business processes by orchestrating different AI capabilities.
Whether you're looking to automate content creation, streamline customer service, or process large amounts of data, understanding the performance and cost of underlying models like Gemini 2.5 Flash is a key step. MindPal provides the framework to bring these models together and build your own AI workforce. You can explore different pricing plans to find the right fit for your needs and even get professional setup support to get started quickly.
Conclusion
Gemini 2.5 Flash appears to be a compelling addition to the landscape of large language models, offering a strong balance of performance and cost-efficiency. Its "thinking" capabilities, combined with flexible pricing and solid performance across various benchmarks, make it a valuable tool for developers and businesses looking to harness the power of AI for a wide range of applications.
As AI continues to evolve, staying informed about the capabilities of models like Gemini 2.5 Flash is essential. Platforms like MindPal empower you to take these models and build custom solutions that can truly transform your productivity and business operations.